by Rob Mohr, AccuRev
In one of many travels and customer visits, I came across a very cool way that AccuRev was helping to improve the way development teams do their work. To be more specific, this group was using Change Packages integrated with the JIRA Issue Tracking system to manage changes across their various product releases. They also used CruiseControl for continuous integration that would kick off nightly builds and notify the team with the results of the build.
From what they told me, the success of builds has significantly improved since they started using AccuRev because of the ability for the developers to work in their own private workspaces where they can integrate and unit test before promoting their changes for the rest of the team. Although broken builds are, for the most part, a thing of the past, they will still occur once in a while and need to be fixed ASAP.
Here is how they do it with AccuRev
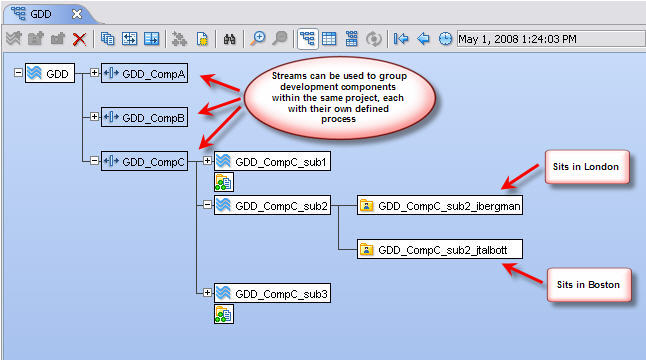
The stream structure below is a simpler view of their overall software development process, but will be sufficient to show the use case.
Promoting to the Integration Stream
To start, the 4 developers below have made changes in their workspaces that will be promoted and associated to 4 different issues.

As you can see below, the integration stream (EntSoft_Client_Int) is “aware” of which issues are active in the stream. These are the new “change packages” introduced in the stream to be included in the next nightly build.

Build Fails in the Integration Stream
The next morning, the team is notified that last nights build failed via an email notification from CruiseControl. They have also scripted CruiseControl to automatically enable a time based stream called the “Temp_Fix_Build” stream and assign the appropriate transaction number to rollback the change packages from last night.

Assign the Developer to Fix the Build
One of the developers creates a workspace on the Temp_Fix_Build and “change palettes” over each change package one at a time. This gives them the ability to mix and match change packages together to determine which one of them is the problem.

Problem Solved
After the culprit is fixed, the repaired change package(s) are promoted back into the integration stream for all to share.




 Posted by rmohr
Posted by rmohr 



 Stumble It!
Stumble It!